


- 827.62 KB
- 10页


- 1、本文档共5页,可阅读全部内容。
- 2、本文档内容版权归属内容提供方,所产生的收益全部归内容提供方所有。如果您对本文有版权争议,可选择认领,认领后既往收益都归您。
- 3、本文档由用户上传,本站不保证质量和数量令人满意,可能有诸多瑕疵,付费之前,请仔细先通过免费阅读内容等途径辨别内容交易风险。如存在严重挂羊头卖狗肉之情形,可联系本站下载客服投诉处理。
- 文档侵权举报电话:19940600175。
'智能无人避障车项目报告任超,杜聿博一、项目概述本项目旨在开发出能够通过双目摄像头传感器自行识别障碍物并减速或停车避让的智能无人车。项目组有意在此基础上继续开发,最终达到将无人驾驶前沿技术和传统技术相结合,使自动驾驶技术能够落地日常生活,低成本地实现轻量级配送服务的智能自动化无人配送车,并且为此做了一些努力,将一同在下文说明。二、项目内容1.立项依据最近电商市场不断发展,物流行业也覆盖全国,将从传统的人力物流向现代智慧物流体系转型。在“互联网+"、中国制造与工业4.0等政策影响下,智慧物流也因此成为物流行业转型重点。但是现在底层物流仍然依靠原始的人力运输,成本很高且非常低效,为了节省成本,快递公司通常会设置取货点,快递员送到取货点后用户自行取件,对于居住点离快递点比较远又没有时间的用户来说不够方便,因此一种低成本的配送方式是很必要的。与此同时,无人驾驶技术趋近成熟,智能图像识别技术发展很快,所以发展基于图像识别技术导航的智能无人配送车成为一种可能的解决方案。本次先实现避障的功能,为最终达到智能无人配送车打下基础。
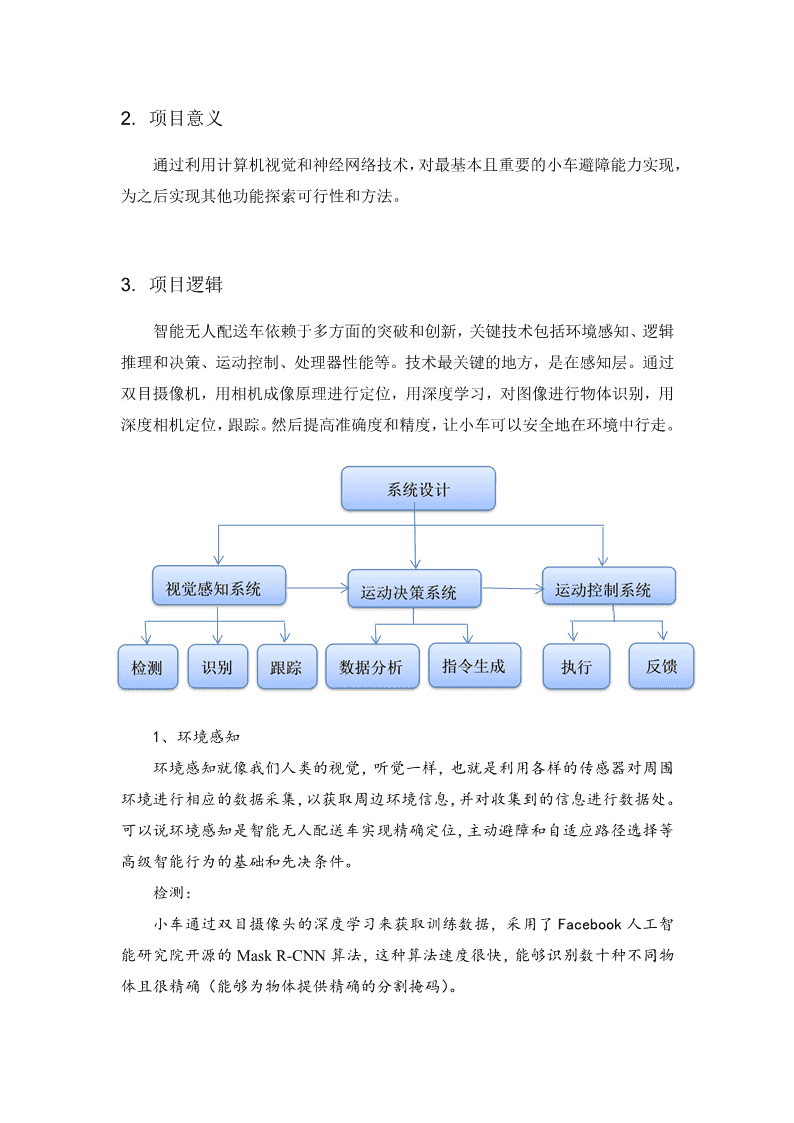
2.项目意义通过利用计算机视觉和神经网络技术,对最基本且重要的小车避障能力实现,为之后实现其他功能探索可行性和方法。3.项目逻辑智能无人配送车依赖于多方面的突破和创新,关键技术包括环境感知、逻辑推理和决策、运动控制、处理器性能等。技术最关键的地方,是在感知层。通过双目摄像机,用相机成像原理进行定位,用深度学习,对图像进行物体识别,用深度相机定位,跟踪。然后提高准确度和精度,让小车可以安全地在环境中行走。1、环境感知环境感知就像我们人类的视觉,听觉一样,也就是利用各样的传感器对周围环境进行相应的数据采集,以获取周边环境信息,并对收集到的信息进行数据处。可以说环境感知是智能无人配送车实现精确定位,主动避障和自适应路径选择等高级智能行为的基础和先决条件。检测:小车通过双目摄像头的深度学习来获取训练数据,采用了Facebook人工智能研究院开源的MaskR-CNN算法,这种算法速度很快,能够识别数十种不同物体且很精确(能够为物体提供精确的分割掩码)。
识别:算法中搭载2个MaskR-CNN模型,一个利用双目摄像头,通过COCO2014数据集训练对障碍物的识别,通过对比左右摄像头的图像确定目标物体的深度(距离),因此可以对车前方的障碍物进行识别,测距,从而进行避障;另一个通过在科大东区实地采集的白线照片生成数据集训练对白线的识别,通过对路边地标线(白线)的识别和定向,可以识别路的走向,再借助陀螺仪提高精度,从而实现导航。(图:摄像头得到的原图和处理后的图片对比(白线,障碍物))跟踪:通过对比连续的两张取到的图片,在图中匹配识别到的物体。识别的依据主要为被识别区域的彩色直方图,将直方图配对的认为是同一个物体,这样可以计算出它的运动速度,从而估计其轨迹。2、运动决策设定小车的状态集合为:I={直线正常速度行驶、直线低速行驶、直线微调、直角拐弯、停车}。小车设置内外安全范围,外层之外的障碍物视为无,内层之外外层之内的进行跟踪,内层之内的视为危险。若测量没有障碍物影响轨迹,并且直线方向与小车坐标系中小车前进方向夹角在正负10度范围内,则小车处于直线正常速度行驶状态;如果检测到有物体在小车的外层安全距离范围内,那么小车处于直线低速行驶状态;如果小车检测到白线方向偏离,或者小车到白线的距离不在正常范围内,那么进入直线微调状
态;如果根据地图检测到行驶到了路口,则进入直角拐弯状态;如果有任何物体进入小车的内层安全距离范围内,则进入停车状态。停车状态优先于其他所有状态。3、运动控制控制指令由主机通过USB串口与Arduino通信,Arduino向电机发送指令来操控电机。两边履带的转速,由电机编码器实时向决策系统反馈,转角由陀螺仪向决策系统反馈。例如转向指令,在底层封装好,上位机只需要调用相应的接口即可。最后通过各个部分共同配合,完成对小车较为精准的控制。4.实物结构(图:小车实物图)小车主要有上下位机,动力系统,传感器组成。双目摄像头主机散热风扇ups电源底盘1、上位机为了满足实时地处理摄像头取到的图片,要求安装GPU且对GPU的要求很高,因此不得不采用带有GTX1080ti的GPU的主机电脑作为上位机,小车和电脑共同由UPS电源作为供电设备。2、下位机
下位机采用Arduibo控制电机,采用USB串口与主机通信。3、动力系统小车选择了含有履带的底盘作为动力装置。四段履带由四个电机控制,电机通过编码器,与Arduino连接。在编码器中,将一边的两个履带封装在一起,统一控制。编码器可以记录两边履带所行走的圈数。测量每圈的周长,则可以根据编码器算出前行的距离。小车的转向,靠两边履带转动的速度差来实现。4、传感器传感器以双目摄像机为主要传感器,再添加一个陀螺仪辅助转弯。识别物体与测距,双目摄像头都可以完成。在最后控制阶段,因为仅通过图像,无法精确得到小车的转角,所以用陀螺仪配合控制转角。双目摄像头通过一个USB接口,向主机发送一张完整图片,这张图由双目摄像机的两个摄像头在同一时刻捕捉到的画面进行左右拼接而成。5.部分算法思想1、MaskR-CNN算法1、反卷积神经网络通过卷积可以将图片的细节光滑化,从而提取出图像特征并降维;而通过反卷积可以将图片细节还原,从而达到升维。其中一种方法执行的过程分为两步:双线性插值对低维矩阵进行行方向和列方向的线性插值,从而得到升维的矩阵。如图所示,对2*2矩阵进行双线性插值,得到5*5的矩阵,黄色位置为原矩阵。0.511.522.51.522.533.523双线性插值2.533.544.5453.544.555.54.555.566.5
一次卷积对插值得到的矩阵进行一次卷积降维,但是仍然保证比原矩阵维数增加,这样就得到了反卷积的结果,原矩阵被放大一倍。如图所示,对上图中的插值后矩阵用I为卷积核进行卷积,得到2四维矩阵。0.511.522.52.53.54.55.51.522.533.5I24.55.56.57.52.533.544.56.57.58.59.53.544.555.58.59.510.511.54.555.566.52、全卷积神经网络全卷积神经网络在卷积层,池化层上与卷积神经网络类似,但是在全连接层上不再使用与输入矩阵维数相同,而是改为一维矩阵,使得通过全连接层的矩阵维数不变。全卷积神经网络的结构如图所示,输入图片经过多次卷积,最后通道数变为4096,再经过两层全卷积网络,输出通道数为N。输出的N是所有检测物体的类别数目。(图:全卷积网络结构)全卷积神经网络的最后一层即为反卷积层。这一层将最后通过全卷
积层输出的矩阵,反卷积为第四层卷积层输出大小,将第四层的输出与反卷积后的矩阵相应位置相加,再反卷积为第三层卷积层输出的大小,与第三层输出结果对应位置相加后,直接反卷积生成原图大小。最后通过全卷积神经网络最后的反卷积层输出的结果,共有N个和原图大小相同的矩阵。这N个矩阵分别与N个类别对应,在矩阵上用0,1表示物体所在位置。即可达到监督训练的目的,从而训练出整个全卷积神经网络。(图:反卷积层)这种算法的最大优势在于理论上能对物体进行像素级别的分割,这为MaskR-CNN的实现提供了基础。3、MaskR-CNNMaskR-CNN以FasterR-CNN为基础,将RoiPooling层换为了RoiAlign,这使得选取出的候选框的缩放比例可以不为整数,从而提高坐标位置的精确度。在提取出候选框之后,MaskR-CNN在RoiAlign层之后,添加了并行的全卷积网络,在检测识别的同时,对候选框内的图像进行语义分割,且这个并行过程的运算时间远小于整个过程的时间。MaskR-CNN则是利用FasterR-CNN产生的候选框和后续类别判断体系,同时将FCN应用于每一个候选框。这样大幅度提高了掩码分割的准确率。从而实现了物体检测端对端以及像素级别分割的效果。(图:MaskR-CNN效果示意图)
2、白线的识别要识别白线,只要对白线的边界进行定位。由于白线的边界是粗糙的,并不是严格直线,因此需要对图片中白线边界除去噪音,得到直线来确定白线的边界。以左侧边界为例,做法为先以L/n为间隔,对白线进行扫描线算法,得到扫描线和白线左侧边界的n个交点。然后对这n个交点做最小二乘拟合,解出直线方程ax+by=1000中的未知量a、b,则这个方程代表的直线作为白线左侧边界。(图:白线的扫描线和拟合的直线)3、摄像机坐标系到地面坐标系变换所有小车的运行数据应当在地面坐标系下运算,而小车从外界接收到的信息都是摄像机坐标下的,所以需要对两个坐标系下的坐标进行变换。考虑到摄像机坐标系下路的两侧白线不是平行的,这个变换应当在地面坐标系下使两侧白线平行,在刚体变换下这是做不到的。为了解决这个问题,我们将这两个坐标系放在复平面下,那么就可以使用分式线性变换:azbwf(z),adbc0czd若w=u+vi,z=x+yi,从上式中解出实部和虚部,并用x,y表示,有axayaaxaya111213212223u,vaxayaaxaya313233313233
只要通过实验测出以上九个参数,就能得到变换公式。不妨设a1,在小车的相机中,双目两幅图只需要选定一幅图进行标定即33可。标定如图所示,选取瓷砖地面作为度量依据,在每块砖的顶点处贴黑色胶带。设定小车最前端中点为地面坐标系原点,测量每个点相较于原点的位置坐标。再对应于图像中该点的位置,取得14个点构建方程组,用最小二乘法求得以上参数。(图:瓷砖标定(摄像头视角))yxo三、项目团队姓名单位学院分工杜聿博中国科技大学物理学院图像算法任超中国科技大学数学学院传输算法周肖宇中国科技大学数学学院图像算法李权熹中国科技大学物理学院标注软件凌军中国科技大学信息学院传输算法张俊合肥工业大学工程学院硬件控制沈佳杏中国科技大学工程学院硬件控制任慧明安徽中医药大学信息学院数据标注
四、讨论1、存在的不足由于时间,硬件和知识水平的限制,目前项目有如下未能达到要求处:由于GPS精度过低,目前只能在既定的路线上运作(暂时为科大东区郭沫若路+孺子牛路的一部分);训练数据库采样有限,因此只能在良好条件下(晴朗白天)识别;由于目前不能精准地测出障碍物的距离,导致跟踪不准确而失去意义;由于网络状况的限制,小车只能和主机只能用usb接口通信(而不是更便捷的远端服务器),这意味着小车要承载沉重的主机,削弱了载物能力;遇到障碍物只能做到简单的停车而不能绕开;决策系统还比较简单,还不具备复杂条件下的运作能力;2、感想参加这个项目让笔者提升很多。项目内有很多学识渊博,经验丰富的大神,他们不厌其烦地对笔者进行指导,使得笔者在很短的时间内就对计算机视觉和神经网络有了一定的认识,并在各个方面都给予帮助,在此表示感谢;由于笔者本人水平有限,大多做一些搬砖的活,但是即使这样笔者也感觉到在短期内提升很多,通过对算法的编程实现,很快就提升了对算法和编程软件的认识,这是通过书本学不到的。这证明了实践是提升的最有效手段;在这个项目中,很少能有解决精准的、明确的问题的机会,大部分时候要解决的问题都只有模糊、概括的表述,这是与之前的学习不同的,也是做研究时的实际情况。笔者在这样的训练中,也增强了从应用环境中抽象数学问题的能力;这个项目已经有了一些成果,但是可改进的地方还非常多,如稳定的网络环境以将主机搭载在远端,加入其他的传感器或提升对图像识别的训练以适应更多的路面情况等,这些都会在条件允许时考虑解决。'
您可能关注的文档
- 服装专业实训项目报告
- 软件开发实践课程项目报告(参考模板)
- 网站会员注册于登陆项目报告
- 土地一班5组帝景豪庭项目报告书
- 天盟塑料综合利用项目报告
- 三溪村历史的调查与建筑保护研究项目报告
- 嘉兴项目报告书可行性研究报告策划报告
- 海淀区上庄N35-N46地块定向安置房项目报告表pdf
- 个人项目报告模板(专业实训六)0416
- 有机肥建设项目报告表
- 安全网生产加工项目报告表
- 北京工商银行珠市口支行局域网项目报告书
- 基于内容的图像分类项目报告
- 世联厦门禹洲高尔夫球场配套居住社区项目报告下
- 伟业顾问07年北京市高粱桥街项目报告及营销推广
- 金属工艺及机制基础三级项目报告偏心轴加工工艺制定
- 精益6西格玛-黑带项目报告
- 杨鹏真项目报告